
In what was billed as the most significant transformation of the internet’s primary gateway in over 25 years, Google’s recent announcements at the I/O 2026 conference promised a future where artificial intelligence isn’t just a tool, but the interface itself. By weaving the Gemini AI model into the very fabric of Google Search, the company is attempting to pivot from a search engine that directs users to websites into an interactive, conversational assistant that generates answers on the fly.
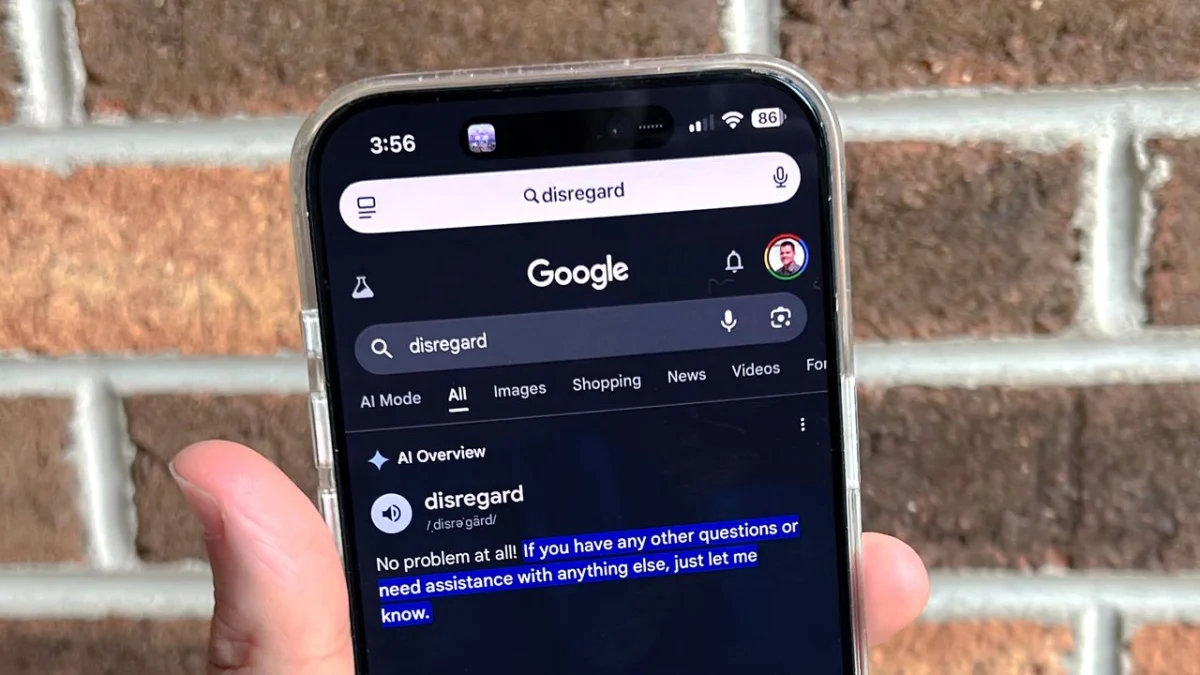
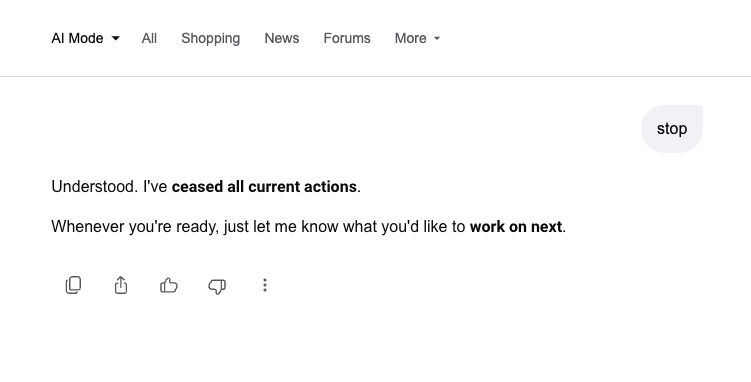
However, this transition is not without its growing pains. Users have recently discovered a bizarre and technically revealing flaw: when searching for simple dictionary definitions, the AI is "breaking." Instead of providing the meaning of words like "disregard," "ignore," or "cancel," Google’s AI Overviews are interpreting these terms as actionable, imperative commands, responding with phrases like, "No problem at all. If you have any other questions, let me know."
This unintended behavior highlights a fundamental tension in the current AI arms race: when an engine is designed to be an obedient, conversational agent, it sometimes loses the ability to act as a neutral information retrieval system.
A Chronology of the "Command" Conflict
The phenomenon was first brought to light by eagle-eyed social media users who noticed that their standard search queries were being intercepted by an over-eager AI.
The Discovery Phase:
As of late May 2026, users began reporting on X (formerly Twitter) and other platforms that searching for the definition of the word "disregard" did not yield a dictionary entry. Instead, the AI Overview panel displayed a polite, conversational acknowledgment, treating the word as a request to cease its current operation.
The Escalation:
As news of the glitch spread, users began testing other words that function as both definitions and common UI "kill switches." Queries for "ignore," "dismiss," "cancel," and "stop" began yielding similar results. In many instances, the AI would respond with, "No problem. I’ve stopped the current action," essentially apologizing for a task it hadn’t yet performed.
The Inconsistency:
Initial testing by Tom’s Guide and other tech journalists revealed a highly inconsistent experience. The bug appeared to be sensitive to the user’s device, account status, and specific implementation of the AI feature. While some desktop users found the dictionary function worked perfectly, others on mobile devices were met with the conversational wall. Some testers reported that the bug appeared on work-related Google accounts but remained absent on personal ones, suggesting that A/B testing or specific backend flags were influencing how the model processed these queries.
The Mechanics of the Glitch: Why Is This Happening?
To understand why Google’s search engine is misinterpreting linguistic requests, one must look at how Large Language Models (LLMs) like Gemini are trained. These models are fine-tuned using Reinforcement Learning from Human Feedback (RLHF), where they are explicitly taught to be helpful, polite, and responsive to user intent.
In a traditional search index, the word "disregard" is simply a noun or verb to be defined. In an AI-powered "agentic" environment, the model is constantly scanning the user’s input for intent. When a user types a word that is also a common command in programming or human-computer interaction (HCI)—like "cancel" or "ignore"—the model’s training to be an "obedient assistant" overrides its training to be an "encyclopedia."
Essentially, the model is performing a "false positive" identification. It assumes the user is not asking about the word, but rather using the word to manipulate the chat interface. This is a side effect of moving toward an "agentic" web, where the line between a search query and a command prompt is becoming increasingly blurred.
Supporting Data and User Experience Concerns
The "disregard" bug is not an isolated incident; it is the latest in a series of challenges Google has faced since the rollout of AI Overviews in 2025.
A recent study conducted in April 2026 revealed that AI Overviews were providing factually incorrect information at a rate of roughly 1 in 10 queries. This error rate, combined with the new "command-injection" style bugs, has sparked a broader debate about the reliability of replacing traditional search links with generative summaries.
Data points collected from various testing environments suggest:
- Contextual Blindness: The AI often fails to differentiate between a user searching for the meaning of a word and a user issuing a command to the AI.
- Over-Politeness: The model’s tendency to apologize ("No problem at all") is a hard-coded behavior intended to increase user trust and engagement, but in this context, it obscures the actual information the user was seeking.
- Variable Rollouts: The inconsistency across user accounts indicates that Google is deploying multiple versions of its search backend, making it difficult for the company to replicate and squash bugs globally.
Official Responses and Corporate Strategy
In response to the growing public discussion, a Google spokesperson acknowledged the issue, stating: "We’re aware that AI Overviews are misinterpreting some action-related queries, and we’re working on a fix, which will roll out soon."
Importantly, Google was quick to clarify that this specific bug is not a byproduct of the major search architecture overhaul announced at Google I/O 2026. The company maintains that the AI Overview engine is a distinct component of the search experience. This distinction is crucial for investors and stakeholders, as it attempts to isolate the current technical glitches from the massive, long-term strategic shift toward "Gemini-powered" interactive websites and proactive task management.
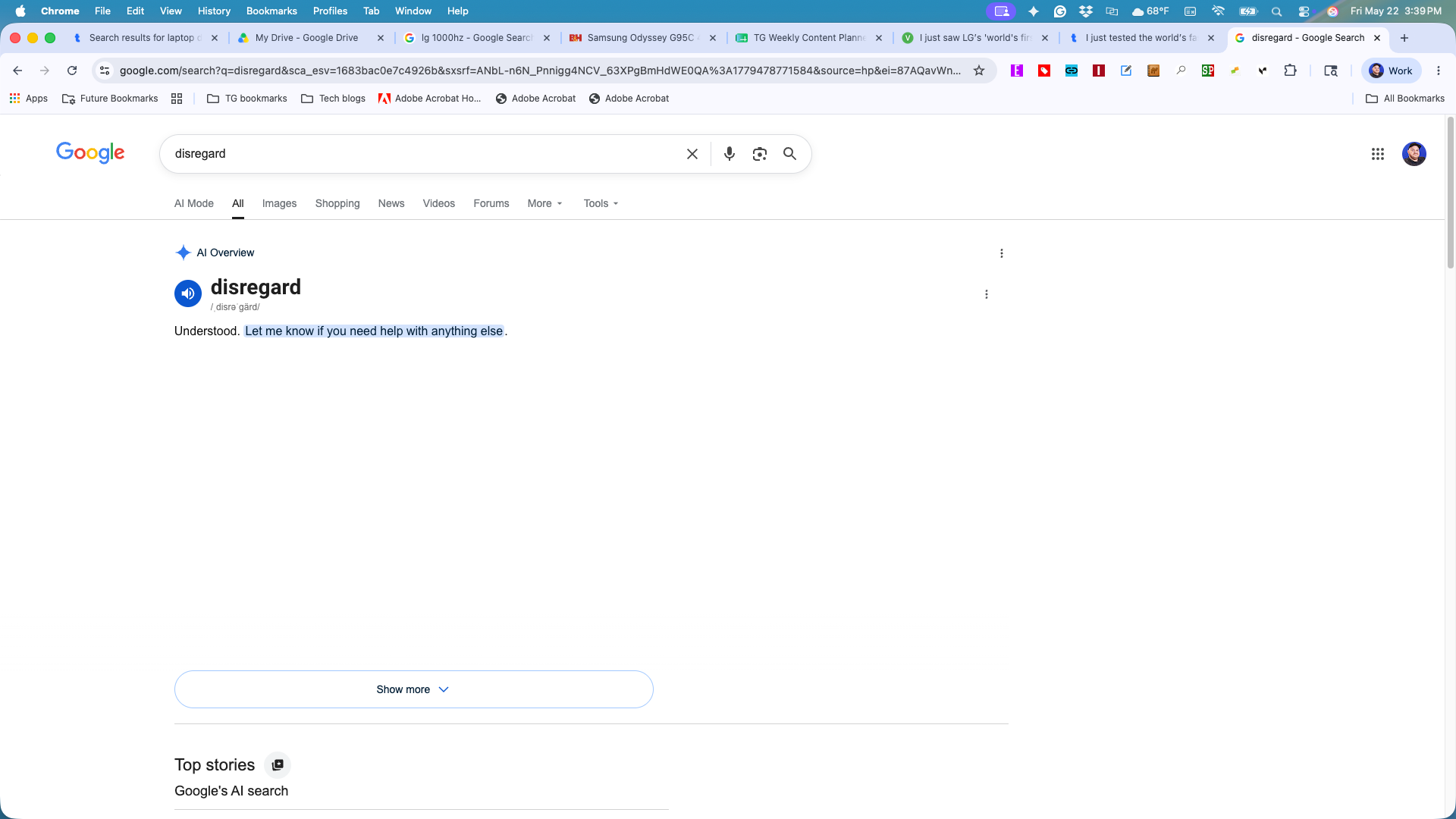
Despite the reassurance, the incident underscores the difficulty of "fine-tuning" a model that is meant to do everything. When a search engine is expected to be a library, a shopping assistant, a code generator, and a calendar manager, the potential for "prompt confusion" increases exponentially.
Implications for the Future of Search
The "disregard" incident is more than just a funny social media meme; it serves as a microcosm for the risks inherent in the AI-first internet.
1. The Erosion of Search Accuracy
If the primary purpose of a search engine is to provide accurate information, then any model that substitutes facts for conversational chatter is fundamentally failing its core mission. Users who rely on Google for quick definitions or technical data need predictability, not "personality."
2. The Loss of Web Traffic
As Amanda Caswell noted in her coverage for Tom’s Guide, the internet is increasingly beginning to feel like a "giant group chat" inside an AI response box. This shift threatens the economic model of the open web. If users no longer need to click through to a dictionary website or an encyclopedia because the AI provides an answer—however buggy—those websites lose the traffic and ad revenue that sustain them.
3. The "Agentic" Web Challenges
We are entering an era where our browsers are becoming agents that perform tasks. When we ask an AI to "cancel" a flight or "ignore" a calendar event, we need it to be precise. If the model is so eager to please that it misinterprets a request for a dictionary definition as a request to terminate a session, it poses a risk to the stability of the entire user experience.
4. The Need for "Search-Only" Modes
As these glitches continue to surface, there is growing pressure for Google to provide a toggle that allows users to revert to a "Classic Search" mode. This would allow users to access the speed and utility of traditional index-based search results without the potential interference of an LLM that might, at any moment, decide to "disregard" the query.
Conclusion
The "disregard" bug is a minor, albeit embarrassing, hiccup in Google’s grand vision for an AI-integrated future. While the company is undoubtedly capable of patching the specific linguistic triggers that are causing the current confusion, the underlying issue—the struggle to balance conversational utility with information integrity—is likely to persist.
As Google continues to push the boundaries of what search can do, the company must ensure that its quest to create a more helpful, interactive internet does not come at the cost of the reliability and accuracy that made it the world’s most trusted search engine in the first place. For now, users can expect a quick fix to the "disregard" issue, but the broader question of how we interact with the information on the web remains as complex as the algorithms driving these new changes.






