
For years, the Network Attached Storage (NAS) unit has been the "set it and forget it" workhorse of the modern home lab. Once the storage pools are initialized, the permissions set, and the services humming along, these machines often retreat into the background, becoming little more than silent, blinking boxes in a closet. However, as home lab enthusiasts push the boundaries of local infrastructure, many are realizing that these storage giants are often underutilized.
A NAS generates an immense amount of diagnostic data—logs, SMART reports, playback history, and system health metrics—that remains largely invisible until a critical failure occurs. By integrating local Large Language Models (LLMs) into these environments, sysadmins are finally bridging the gap between raw data and actionable intelligence.
The Evolution of the Home Server: From Storage to Intelligence
The transition from a passive storage device to an active, conversational server is not merely a novelty; it is a fundamental shift in how we manage complex home networks. For many, the NAS is the central nervous system of the digital home, managing everything from family Plex media libraries to critical off-site backup synchronizations.
Historically, monitoring these systems required a tedious routine: logging into web dashboards, scouring through cryptic text-based logs, or manually parsing SQLite databases. For the average user, this complexity often leads to "monitoring fatigue," where logs go unread until a drive failure or a service outage forces a reaction.
By leveraging the compute power of repurposed hardware—typically aging gaming rigs that are more than capable of handling modern inference tasks—enthusiasts are deploying local LLM ecosystems like Ollama. This allows the server to act as its own administrator, capable of explaining its current state in plain, human-readable language.
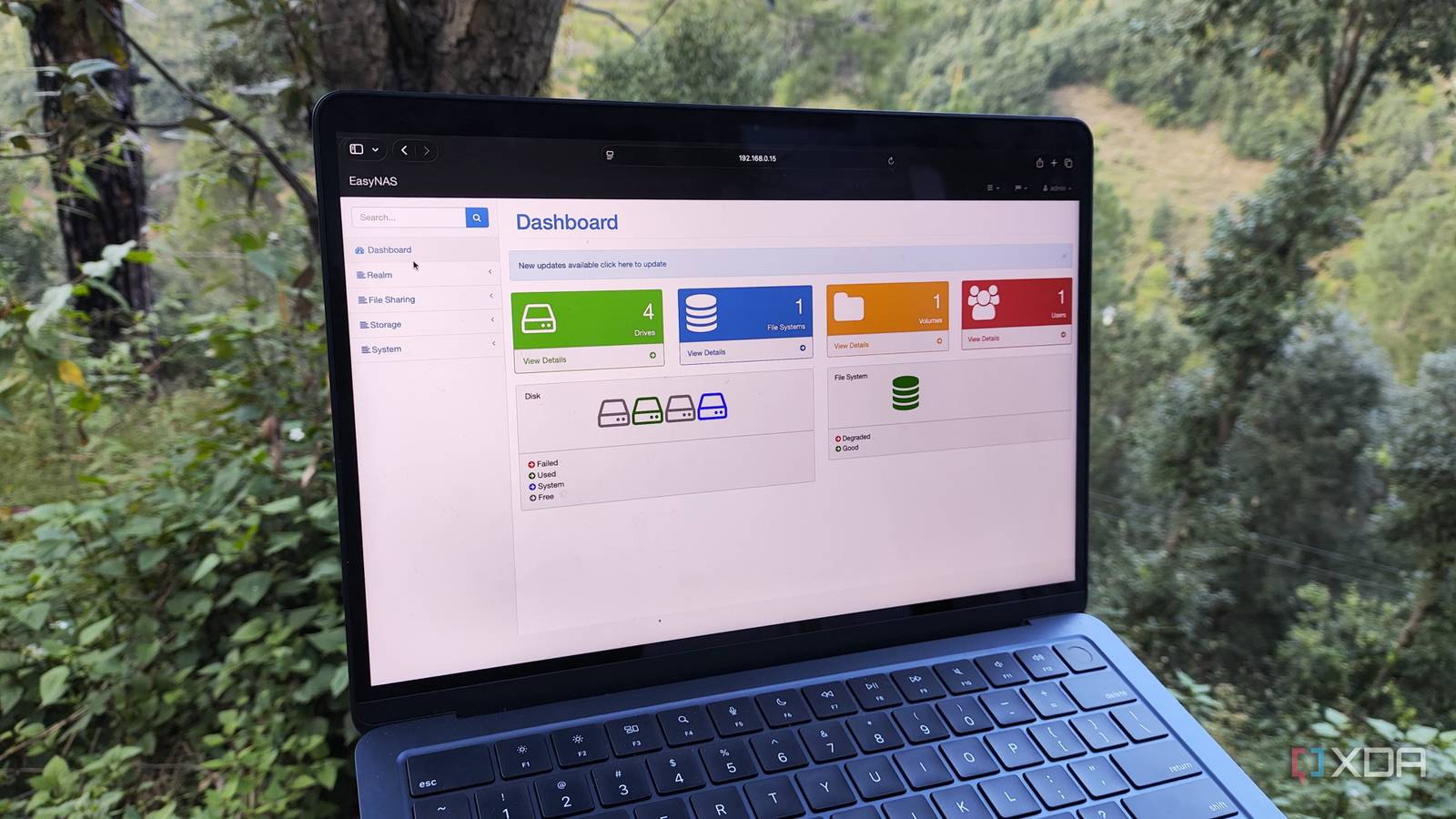
Chronology: Building the Conversational Infrastructure
The journey to an intelligent NAS typically follows a structured path of implementation, moving from simple data collection to complex natural language interpretation.
Phase 1: Hardware Assessment and Model Selection
The process begins with an audit of the host machine’s resources. Since most home NAS units are repurposed x86-based desktops or towers, they often possess the CPU cycles and RAM overhead required to run quantized models. The deployment of Ollama serves as the backbone for the inference engine, chosen for its lightweight footprint and ease of API integration.
Choosing a model like Llama 3 (or smaller, more specialized variants) is critical. While these models may not win prizes for creative writing or complex reasoning, they are perfectly suited for the task of pattern recognition and log summarization.
Phase 2: The Logic Layer
Once the model is active, the next step is connecting it to the system’s "brain." This is achieved through custom Python scripts. These scripts act as the middleware, performing three primary tasks:
- Log Ingestion: Periodically pulling data from TrueNAS system logs or parsing Plex’s SQLite playback databases.
- Contextual Formatting: Converting raw, often messy, technical data into a structured format that the LLM can interpret without hallucinating.
- API Communication: Sending this data to the Ollama local endpoint and retrieving the summary or insight.
Phase 3: The Interface
To make the information accessible, the integration of Open WebUI provides a familiar, chat-like interface. This moves the interaction away from the command line, allowing users to query their server from any browser on the local network.

Supporting Data: Efficiency and Resource Allocation
One of the primary concerns regarding local AI integration is the "overhead cost." Does adding an LLM to a NAS degrade the primary function of the server?
In practice, the strain is minimal. Because these tasks are asynchronous—nobody is waiting for a real-time response to a SMART check—the model can be throttled or run with low priority. Furthermore, because the LLM processes data locally, there is no latency associated with cloud API calls, and—more importantly—sensitive logs never leave the local network.
Data shows that for a home server, the most frequent queries involve:
- System Health Summaries: Asking, "Have there been any disk errors in the last 48 hours?"
- Media Insights: Asking, "What have the top three most-watched movies been this week?"
- Operational Audits: Asking, "Did the backup job to the cloud finish successfully, and if not, what was the error code?"
Implications for the Home Lab Ecosystem
The ability for a server to "talk back" changes the role of the sysadmin. It moves the user from being a constant monitor to being an overseer.
Bridging the Gap in Complexity
Modern home labs are becoming increasingly complex. Between Docker containers, virtual machines, and multi-protocol storage, the sheer volume of logs is often too high for human eyes to process effectively. An LLM acts as a filter, highlighting the "signal" within the "noise." When the NAS detects a potential issue—such as a slightly increased temperature in a hard drive or a failed mount attempt—it can present that information immediately, preventing the oversight of minor errors that could cascade into major system failures.
The Hardware Reality Check
It is important to manage expectations. This technology is not a "magic bullet" that will function on every piece of hardware. Low-power ARM-based NAS units, such as those typically found in entry-level Synology or QNAP devices, generally lack the RAM and CPU throughput to run even the smallest quantized models effectively.
This movement is primarily driven by the "Home Lab Prosumer"—those who have recycled high-performance x86 hardware. For these users, the addition of an LLM is essentially a "free" upgrade that turns a dormant pile of silicon into a proactive assistant.
Professional Perspectives on Localized AI
Industry experts have noted that the "Local LLM" trend is the next logical step in server management. By keeping the AI within the local network, users avoid the privacy risks associated with cloud-based diagnostic tools. There is no risk of proprietary system data being used to train third-party models, and the system remains functional even if the internet connection is severed.
However, the challenge remains in the refinement of the prompts. A model is only as good as the context it is given. As the community continues to refine these Python scripts, we are likely to see more standardized tools emerge—open-source plugins that allow for "plug and play" LLM integration for popular NAS operating systems like TrueNAS or Unraid.
Conclusion: The Future of the "Smart" Server
The goal of this project is not to turn a NAS into a sentient entity, but rather to make it a more communicative partner. As we move further into an era where AI is integrated into every facet of our digital lives, it is only natural that our home infrastructure begins to adopt these same technologies.

For those with the hardware to support it, the shift is transformative. The NAS is no longer just a box that sits in the corner, gathering dust and silent data. It is a source of information, a monitor of its own health, and a helpful assistant that ensures the digital home is running at peak performance. By simply asking, "What happened last night?" the modern sysadmin can now receive a clear, concise report, marking the end of the age of the silent server.






