The rapid integration of Artificial Intelligence into the professional landscape has reached a pivotal junction. As of 2026, the question no longer centers on whether AI is useful, but rather, which kind of AI is optimal for specific tasks. For designers, developers, and business strategists, the industry has split into two distinct, competing philosophies: the massive, cloud-based Large Language Models (LLMs) and the agile, privacy-focused Small Language Models (SLMs).
Understanding the dichotomy between these systems is essential for anyone aiming to optimize their workflow, manage operational costs, and maintain a competitive edge in an increasingly automated economy.
The Core Distinction: Power vs. Precision
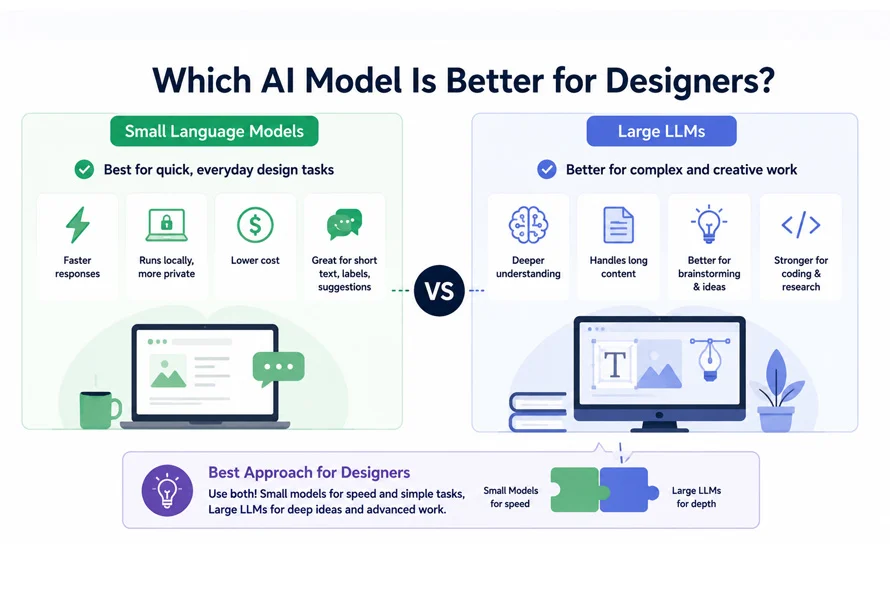
At the heart of the debate is a fundamental difference in architecture. Large Language Models, such as OpenAI’s GPT-4, Claude 3.5, or Google’s Gemini, are gargantuan engines trained on trillions of parameters. They function as "generalists," capable of synthesizing vast amounts of information, solving complex coding puzzles, and engaging in nuanced, creative discourse.
Conversely, Small Language Models (SLMs) are designed for efficiency. By utilizing smaller datasets and fewer parameters, they are stripped of the "bulk" that requires massive GPU server farms to operate. These models prioritize specialized task execution—such as email drafting, image tagging, or local document summarization—often functioning directly on a user’s laptop, mobile device, or browser without the need for an active internet connection.

A Chronology of the Shift: From Cloud-First to Edge-First
The evolution of AI usage has undergone a rapid transformation over the last 24 months:
- 2024 (The Era of Discovery): The market was dominated by massive, centralized cloud models. Accessibility was limited by internet connectivity and high subscription costs.
- 2025 (The Hybrid Transition): As businesses realized the prohibitive costs of cloud-querying, the industry began experimenting with "distillation"—the process of taking the intelligence of a massive model and compressing it into a smaller, faster version.
- 2026 (The Rise of Edge AI): We have entered the era of the "On-Device" model. With the introduction of NPU-integrated chips (Neural Processing Units) in laptops and smartphones, the paradigm has shifted. Companies are now building "Edge AI" solutions that prioritize privacy and near-zero latency, effectively decoupling personal workflows from the volatility of cloud servers.
Supporting Data: Performance and Cost Benchmarking
The divergence between these models is best illustrated through three key metrics:

1. Latency and User Experience
In professional design and development environments, even a 500-millisecond delay can disrupt the "flow state." Cloud-based LLMs, hindered by the round-trip time required to communicate with a remote data center, often struggle with real-time feedback. SLMs, running locally, provide instantaneous responses, making them superior for autocomplete features, live code-checkers, and UI/UX drafting tools.
2. Operational Costs
For enterprise-level deployment, the math is sobering. Running a massive LLM for every customer support query or routine data-entry task incurs massive API consumption fees. Conversely, SLMs are essentially free to run once deployed on local hardware. This shift has allowed startups to scale their AI-integrated products without the unsustainable "cloud tax" that plagued earlier AI ventures.

3. Hardware Requirements
Large models remain the domain of high-end server clusters. However, 2026 has seen a surge in hardware-accelerated local models. Devices like the new generation of "Copilot+ PCs" and mobile devices with dedicated AI silicon can now host sophisticated models that would have required a supercomputer just two years ago.
Implications for Privacy and Security
The most significant impact of the shift toward smaller models is the resolution of the "data-leakage" anxiety. Corporations, legal firms, and healthcare providers have been historically hesitant to feed sensitive proprietary data into public cloud models.

By utilizing local, small-scale models, these entities can now perform deep analysis on sensitive documents in an "air-gapped" environment. Because the data never leaves the user’s device, the risk of data poisoning, unauthorized training on sensitive inputs, or accidental exposure to third-party servers is virtually eliminated. This shift is not just technical; it is a fundamental change in the digital trust architecture of modern business.
The Strategic Role of the Designer
For the creative professional, the choice of model should be dictated by the specific phase of the project:

- Ideation and Synthesis (The Domain of the Large LLM): When building a brand strategy, conducting broad market research, or generating complex creative briefs, a large model’s breadth of knowledge is an asset. It provides the "macro" view necessary for foundational planning.
- Execution and Iteration (The Domain of the SLM): When resizing assets, generating alt-text, performing syntax correction, or managing repetitive design systems, the speed and low cost of a small model make it the preferred tool.
Many designers are now adopting a "layered" approach, utilizing large cloud models to break ground on a project and smaller, local models to manage the high-volume, granular tasks that fill the workday.
Official Industry Outlook: The "Hybrid" Future
Leading industry researchers and tech executives have recently signaled that the future is not a binary choice between small and large, but a sophisticated synthesis of both.

"We are seeing a move toward intelligent routing," notes a lead engineer at a major AI developer. "Future applications will automatically detect the complexity of a user’s prompt. A simple query will be routed to a fast, cheap, local small model. A complex, multi-step problem will be automatically handed off to a massive cloud-based model."
This "Hybrid AI" architecture promises to provide the best of both worlds: the raw intelligence of large-scale systems and the blistering speed and security of local, device-bound models.

AI vs. Human Creativity: The Unchanging Variable
Despite the advancements in model intelligence, a recurring theme in 2026 is the resilience of human input. Regardless of whether an AI is "large" or "small," it remains a tool—a sophisticated instrument for synthesis.
AI excels at processing data, recognizing patterns, and generating output based on existing knowledge. However, it lacks the lived experience, cultural context, and emotional intelligence that define high-level creative work. The most successful professionals in 2026 are not those who ask if AI will replace them, but those who view AI as a junior partner.

Whether using a massive LLM for a global brainstorming session or a small, local model for a quick image-tagging task, the human remains the curator. The AI provides the speed and the raw material, but the human provides the intent, the ethics, and the final, decisive creative spark.
Final Verdict: Choosing Your Toolkit
The era of believing in a "one-size-fits-all" AI model is over.

-
Use a Large LLM (e.g., ChatGPT, Claude) when:
- The task requires deep reasoning or logic.
- You are exploring a topic you are unfamiliar with.
- You need to generate long-form, complex creative content.
- The output does not contain highly sensitive personal or corporate data.
-
Use a Small Language Model (e.g., Local LLMs, Browser-based AI) when:

- The task is repetitive, well-defined, or high-frequency.
- Latency (speed) is a critical factor for your workflow.
- You are handling sensitive or proprietary data that cannot leave your device.
- You are operating in an environment with limited or no internet access.
As we move deeper into 2026, the most successful individuals will be those who master the art of model selection. By treating AI as a spectrum of tools rather than a monolithic entity, you can achieve a level of productivity and efficiency that was impossible just a short time ago. The technology is no longer just "the cloud"—it is now in your hands, on your desk, and in your browser, ready to be deployed exactly where it is needed most.