
The rapid evolution of artificial intelligence has moved beyond a steady march into a frantic sprint. Just weeks after the industry digested the capabilities of Claude Opus 4.7, Anthropic has once again disrupted the landscape with the surprise release of Claude Opus 4.8. This latest iteration is not merely a marginal update; it represents a significant leap in agentic reasoning, coding efficiency, and, perhaps most importantly, the mitigation of "hallucinated" confidence that has plagued large language models (LLMs) since their inception.
As the AI arms race between major players—Anthropic, OpenAI, and Google—reaches a fever pitch, the release of Opus 4.8 serves as a stark reminder that the standard development cycles of the past are obsolete. In the world of generative AI, being "current" is now a fleeting status.
The Main Facts: What Opus 4.8 Brings to the Table
Claude Opus 4.8, announced in late May 2026, focuses heavily on the practical application of AI in professional software development environments. While previous updates often centered on general conversational prowess or creative writing capabilities, the 4.8 release is a targeted strike at the "agentic" workflow—the ability of an AI to autonomously perform multi-step tasks within a terminal or integrated development environment (IDE).
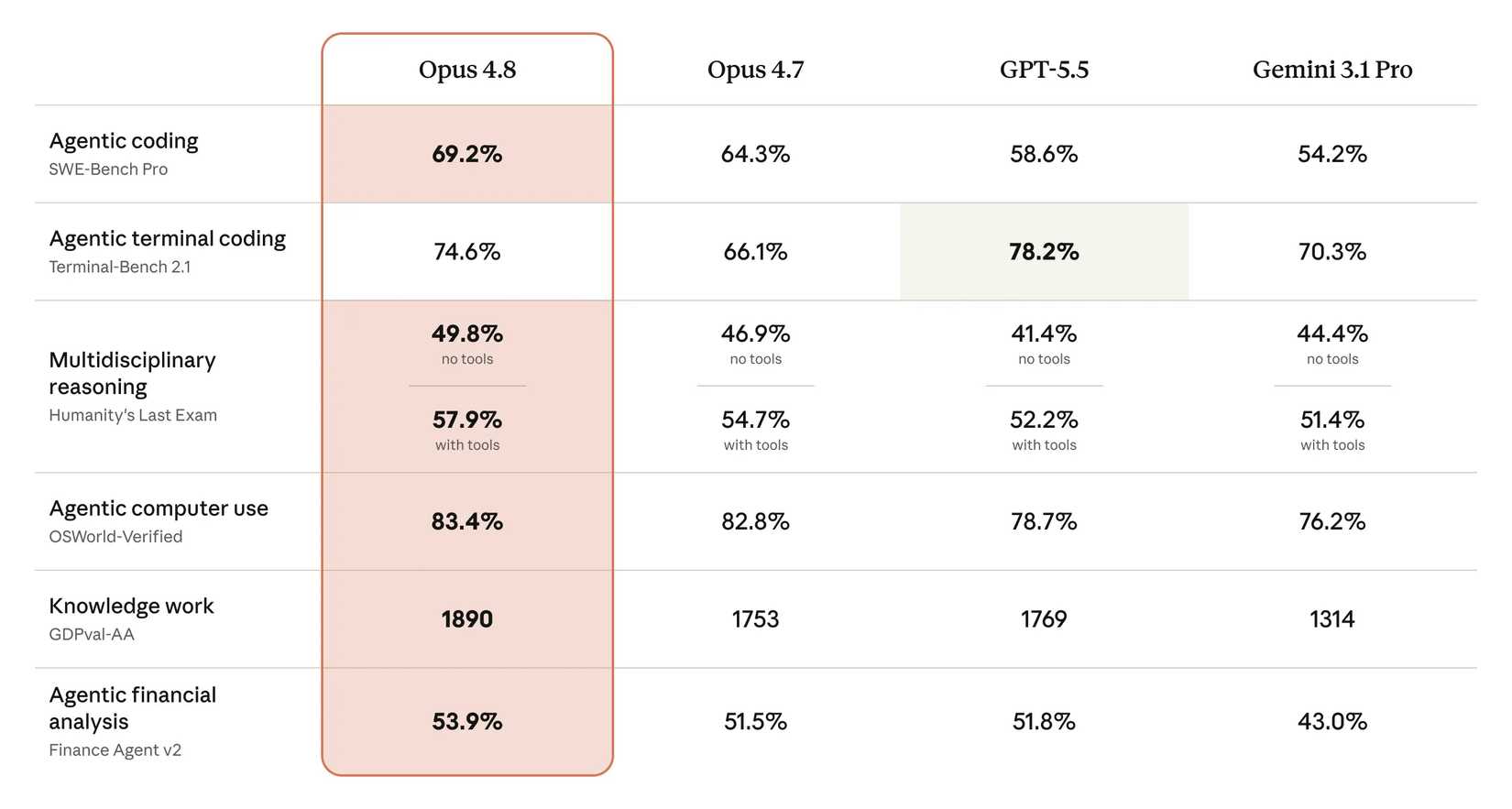
The headline figures are compelling. According to internal benchmarks provided by Anthropic, the model demonstrates a nearly 5% improvement in agentic coding tasks and an 8% boost in terminal-based operations. These are not merely abstract percentage points; they translate to faster debugging, more accurate code generation in complex repositories, and a significantly higher success rate when the model is tasked with executing shell commands to resolve technical issues.
A Chronology of Rapid Deployment
To understand the magnitude of this release, one must look at the timeline of the last few months. In mid-April 2026, the public was introduced to Claude Opus 4.7. At the time, it was touted as the gold standard for reasoning and coding. The industry consensus was that Opus 4.7 had set a high bar, particularly in its ability to handle complex long-context windows.
Yet, within barely six weeks, the development team at Anthropic pushed Opus 4.8 into production. This cadence—a major model release roughly every 30 to 45 days—highlights a fundamental shift in how these companies manage their research and deployment. The "Version 4.x" nomenclature suggests that Anthropic is iterating on a unified architecture, refining weights and fine-tuning datasets in real-time based on the massive influx of user feedback gathered from the millions of developers currently integrating Claude into their daily workflows.
Supporting Data: The Benchmark Battleground
The release of 4.8 was accompanied by updated comparative charts, pitting the new model against the current industry heavyweights, including GPT-5.5 and Gemini 3.1 Pro. The visualization of these metrics reveals a pattern: Anthropic is not just chasing performance; they are optimizing for reliability.
The delta between 4.7 and 4.8 in the category of "agentic terminal coding" is particularly noteworthy. As developers rely more on AI agents to manage server configurations, automate deployment scripts, and perform maintenance tasks, the cost of an error becomes exponentially higher. The 8% performance jump in this specific sector suggests that Anthropic has invested heavily in "sandbox" training—training the model on environments where terminal feedback loop accuracy is the primary metric for success.
Official Responses: The War on Hallucinations
Perhaps the most significant development in Opus 4.8 is not a speed or capability metric, but a behavioral one. For years, the Achilles’ heel of LLMs has been their tendency to speak with total confidence even when they are factually incorrect. This "hallucination" problem has been the primary barrier to wider enterprise adoption.
In their official release notes, Anthropic acknowledged this head-on:

"One of the most prominent improvements in Opus 4.8 is its honesty. We train all our models to be honest—for instance, to avoid making claims that they can’t support. But a general problem with AI models is that they sometimes jump to conclusions, confidently claiming to have made progress in their work despite the evidence being thin."
The company reports that early testers—specifically those working in high-stakes environments—have observed a distinct change in behavior. The model is now more prone to flagging uncertainties. If a command is ambiguous or if the provided code might result in a potential runtime error, Opus 4.8 is now far more likely to pause and ask for clarification rather than attempting a "best guess" execution. This shift from "confident guessing" to "verified output" is a critical milestone for AI maturity.
Implications for the Developer Ecosystem
What does this mean for the average user or software engineer? The implications are three-fold:
1. The Death of the "Stale" Model
Developers can no longer afford to become deeply attached to a specific version of a model. With updates appearing monthly, the learning curve for "prompt engineering" is being replaced by a need for "model-agnostic workflow design." Engineers are learning to build systems that can leverage the newest model at the API level as soon as it drops.
2. The Rise of the Autonomous Agent
The performance gains in agentic coding mean that the AI is moving from being a "code assistant" (someone you ask for snippets) to a "junior developer" (someone you assign tasks to). When a model can navigate a terminal, read documentation, and write tests with an 8% higher success rate, the threshold for delegating full feature implementation becomes much lower.
3. Trust-Based Engineering
By prioritizing "honesty" over raw, unchecked output, Anthropic is clearly positioning Claude as the "enterprise-safe" alternative to its competitors. Businesses that have been hesitant to implement AI due to the risk of "confident, yet wrong" code are likely to find the 4.8 model’s tendency to flag uncertainty as a major selling point. It transforms the AI from a liability into a partner that can be audited.
Conclusion: The Horizon of 4.9
As we look toward the remainder of 2026, the question is not "what will the next model do?" but rather "how fast can the industry adapt to this pace?" If Anthropic continues to release updates at this frequency, the industry will soon face a saturation point where the human capacity to integrate these tools is slower than the machine’s capacity to evolve.
For now, users are encouraged to stress-test the new honesty protocols in Opus 4.8. Whether you are using it to debug a legacy codebase or to architect a new microservice, the improvements in terminal accuracy and self-correction represent a clear signal that the era of "AI as a toy" is firmly in the rearview mirror. We are now in the era of "AI as a teammate." And if the current momentum holds, we will likely be discussing the capabilities of Opus 4.9 before the summer is out.







