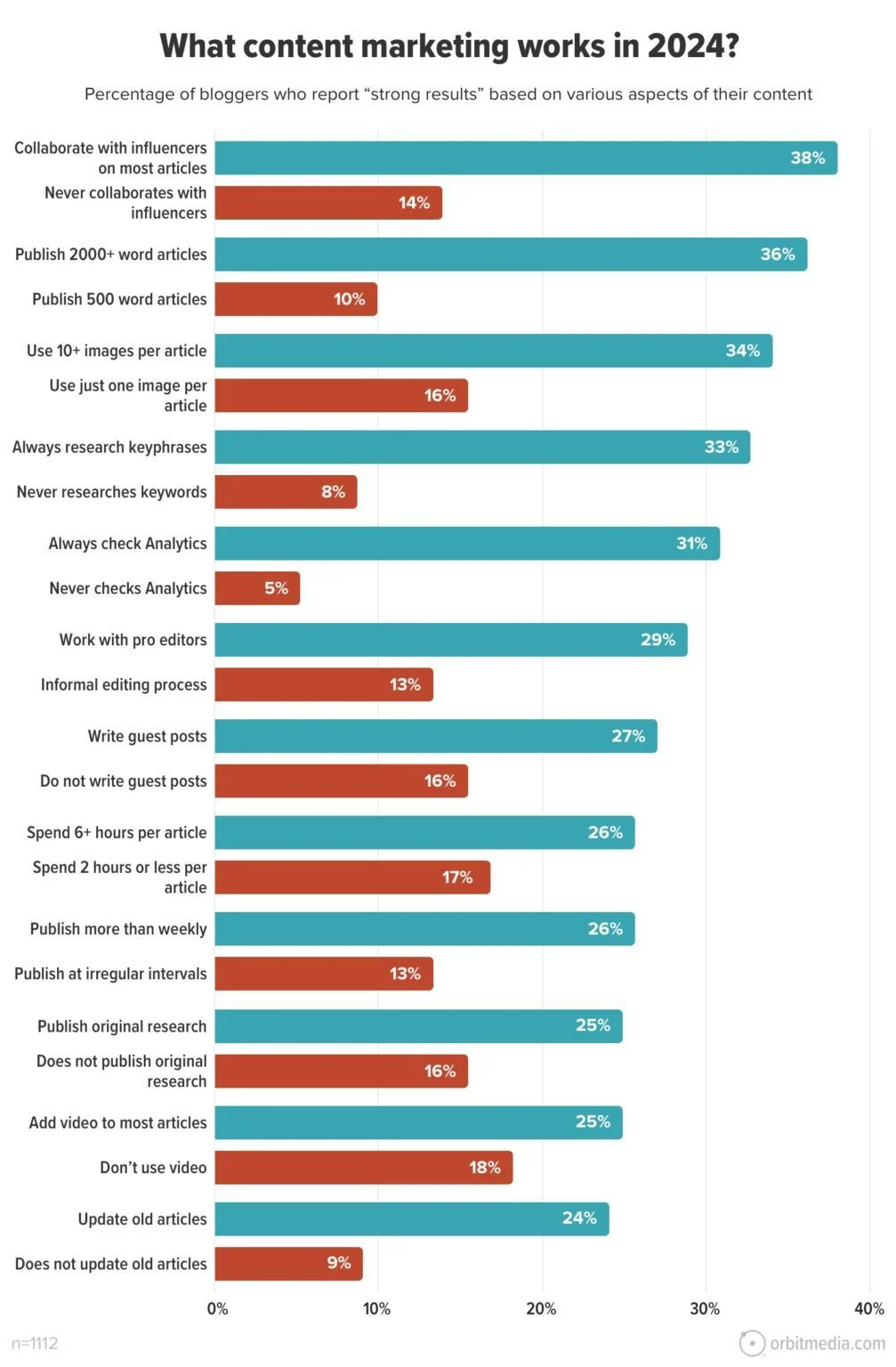
For SEO professionals and e-commerce site owners, few things are as alarming as receiving a notification from Google Search Console (GSC) indicating that thousands of pages are “Indexed, though blocked by robots.txt.” This status—which appears to be a contradiction in terms—often triggers panic, leading webmasters to question their entire technical SEO architecture.
Recently, a WooCommerce site owner faced this exact scenario, reporting over 51,000 affected URLs primarily associated with "add-to-cart" parameters. The confusion led to a high-profile inquiry directed at Google’s Search Advocate, John Mueller. This article dissects the technical nuances of this issue, the risks of over-optimization, and the reality behind Google’s indexing behaviors.
The Core Conflict: Robots.txt vs. Indexing
To understand the frustration of the site owner in question, one must first understand the fundamental mechanics of how Google interacts with websites.
A robots.txt file acts as a gatekeeper. It is a set of instructions telling search engine crawlers which parts of a site they are permitted to visit. When a site owner adds a Disallow rule, they are essentially saying, "Do not crawl this."
However, there is a crucial distinction in the search engine world: Crawling is not the same as Indexing.
If Google finds a URL through an external link or an internal anchor tag, it may choose to include that URL in its index, even if it has never successfully "crawled" the page content due to a robots.txt block. When this happens, Google displays the URL in search results with a note stating that the description is unavailable because the page is blocked by robots.txt. This is the source of the "Indexed, though blocked by robots.txt" status in Search Console.
Chronology of the Issue
The timeline of this specific case mirrors a common pattern seen in large-scale e-commerce operations:
- Discovery: The site owner noticed a sudden spike in GSC notifications regarding 51,000 "Indexed, though blocked by robots.txt" pages.
- Root Cause Identification: The affected URLs were identified as dynamic WooCommerce product pages containing parameters such as
?add-to-cart=. - Initial Reaction: Fearing a negative SEO impact, the site owner attempted to modify the
robots.txtfile, removing theDisallowrules in hopes that Google would process canonical tags and clean up the index. - Community Engagement: Seeking validation, the owner turned to Reddit to ask if removing the block was the right move or if they should implement
noindextags, fearing for their crawl budget. - Official Guidance: John Mueller weighed in, clarifying the necessity—or lack thereof—of indexing these specific URLs.
Analyzing the "Add-to-Cart" Parameter Problem
In e-commerce platforms like WooCommerce, URL parameters are often used for tracking, filtering, or functional actions like adding an item to a cart. These URLs are rarely intended for public search visibility. They are functional, not informational.
Why They Accumulate
The reason the site owner saw 51,000 pages is likely due to the site’s internal linking structure. If the "add-to-cart" buttons or links are present across the site, Googlebot encounters them repeatedly while crawling. Because these URLs are generated dynamically, they can create an almost infinite number of variations, leading to what is known as "URL bloat."
The "Noindex" Fallacy
A common suggestion from community forums is to add a noindex tag to these pages. However, as noted by technical SEO experts, this is often a redundant or impossible task. If a page is blocked via robots.txt, Googlebot cannot "see" the noindex meta tag because it is forbidden from crawling the page in the first place. Therefore, robots.txt blocks and noindex tags are generally mutually exclusive strategies.
Official Responses and Expert Clarification
John Mueller’s response to the inquiry was characteristically pragmatic. He stated: "You don’t need the add-to-cart URLs indexed. Blocking them with robots.txt is fine. Even if they get ‘indexed’ since they’re blocked by robots.txt, it’s unlikely that they’ll be shown in search."
The "Unlikely to Show" Caveat
While Mueller’s assessment is generally correct, it sparked debate among SEO practitioners. Technically, robots.txt does not prevent a URL from appearing in the search results; it only prevents the crawler from accessing the page content. If Google already has the URL and a title tag from external sources, it can technically display that link. However, without the page content, the result will be empty and devoid of useful information, effectively discouraging users from clicking.
Thus, while it is possible for a blocked page to appear, it is statistically improbable that these functional parameters will rank for any meaningful keywords.
Implications for Site Architecture and Crawl Budget
The site owner expressed concern regarding "crawl budget"—the amount of time and resources Google allocates to crawling a specific site.
Does Blocking Improve Crawl Budget?
Yes. By using robots.txt to block irrelevant parameterized URLs, you are preventing Googlebot from wasting its "budget" on pages that provide no SEO value. If Googlebot spends its time crawling thousands of "add-to-cart" pages, it may spend less time crawling your high-priority product descriptions and category pages. Therefore, the robots.txt block is actually a best-practice strategy for large-scale e-commerce sites.
Strategic Recommendations
If you are facing a similar situation, the following steps are recommended:
- Audit Internal Links: Use tools like Screaming Frog or Sitebulb to identify exactly where the "add-to-cart" links are originating. If these links are generated by your theme or a plugin, check if you can modify the link attribute.
- Apply Nofollow: For links that must exist but shouldn’t be indexed, apply the
rel="nofollow"attribute. This sends a strong hint to search engines that they should not follow the link, effectively curbing the propagation of these URLs. - Maintain Robots.txt Blocks: Do not remove the
Disallowrules for functional parameters. The presence of these URLs in Search Console is a warning, not a penalty. It is a report of a condition, not an indicator of a site-wide issue. - Prioritize Canonicalization: Ensure that your "add-to-cart" pages (if they must be crawled) have a canonical tag pointing back to the parent product page. This tells Google which version of the page is the "truth."
Understanding Search Console Reports
A critical takeaway for any SEO professional is to distinguish between warnings and errors.
Google Search Console is designed to be comprehensive. It reports on technical conditions that are technically "abnormal" but often harmless. A 404 error, for instance, is often the correct response for a deleted product. Similarly, an "Indexed, though blocked" status is a reflection of how Googlebot interacts with your instructions. It is not necessarily a signal that your site is being penalized or that your rankings are in jeopardy.
Conclusion: The Joy of Technical SEO
The dilemma of the 51,000 indexed URLs serves as a microcosm of the modern technical SEO landscape. It highlights the tension between site functionality and search engine crawlability.
As John Mueller’s advice suggests, the goal should not be the total elimination of every warning in Search Console, but rather the strategic management of how search engines perceive your site. For e-commerce owners, the priority remains the user experience. If your actual products are indexed correctly and your canonical signals are sound, the presence of technical parameters in GSC should be viewed as a routine maintenance item rather than a cause for alarm.
By utilizing a combination of robots.txt blocks, nofollow hints, and clean site architecture, site owners can ensure that Googlebot focuses its energy on what truly matters: the content that converts visitors into customers.