By Yash Patel | Published June 22, 2026
For years, the gold standard in the artificial intelligence community has been tethered to a singular metric: parameter count. The prevailing logic suggests that if a model is larger, it must be more capable, more nuanced, and inherently superior at solving complex problems. As someone who has spent years integrating self-hosted large language models (LLMs) into my daily professional workflow, I have long been a proponent of this "bigger is better" philosophy.
However, after months of rigorous testing, my perspective has shifted. While larger models indeed possess a higher ceiling for raw reasoning, they often impose a hidden "productivity tax" that can actually hinder the user experience. By comparing a 14B parameter model against a 20B counterpart, I discovered that the pursuit of maximum capability often ignores the most critical component of a functional AI stack: the balance between response latency and output utility.
The Evolution of the Local AI Workflow
To understand why this comparison matters, one must first look at the trajectory of local LLM adoption. Since my early days in software engineering in 2018, I have watched the transition from cloud-based, opaque API calls to the democratization of private, local infrastructure.
A Chronology of Self-Hosting
- 2022-2023 (The Discovery Phase): Early experimentation with local models was defined by massive resource constraints. Running anything above 7B parameters required significant hardware overhead, often resulting in sluggish, unusable performance.
- 2024 (The Optimization Era): The emergence of efficient quantization techniques (GGUF, EXL2) allowed users to run increasingly large models on consumer-grade hardware.
- 2025 (The Integration Phase): Users began moving past mere curiosity, attempting to weave local LLMs into professional IDEs, documentation workflows, and automation scripts.
- 2026 (The Efficiency Pivot): We have now reached a point of saturation where the bottleneck is no longer "Can my computer run this?" but rather "Is this model efficient enough to use for eight hours a day?"
My own journey reflects this progression. Initially, I chased the largest models my RTX 5070 could accommodate. But as my workflow became more dependent on these tools, I realized that a three-second delay on every prompt creates a cognitive friction that negates the convenience of having an AI assistant in the first place.
Testing Methodology: The Real-World Benchmark
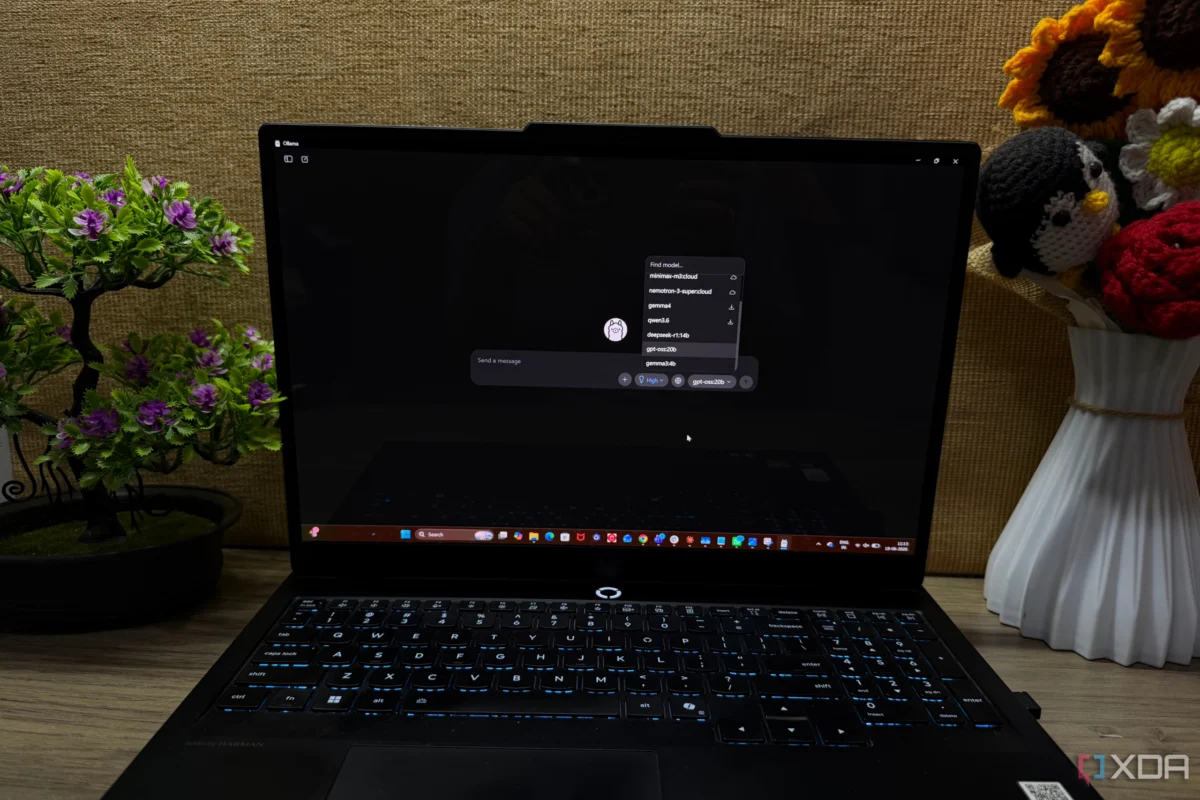
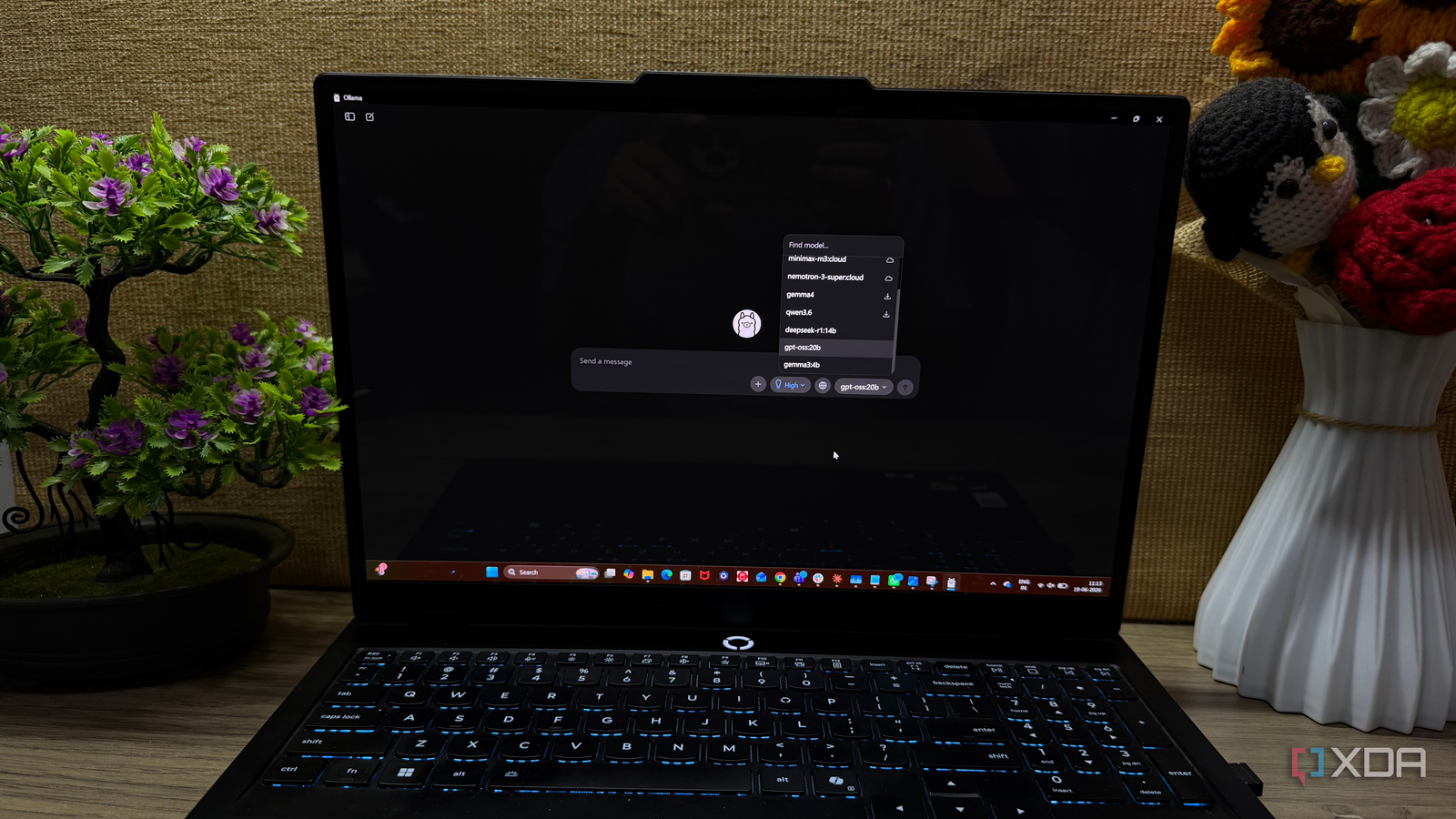
To move beyond abstract benchmarks, I designed a real-world stress test using two distinct models: deepseek-r1:14b and gpt-oss:20b. Both were deployed via Ollama on a system equipped with an NVIDIA RTX 5070 and 32GB of DDR5 RAM.
The goal was to simulate the actual conditions of a professional workspace rather than querying for trivia or creative writing. I focused on three specific categories:
- Documentation Synthesis: Processing dense software changelogs and technical release notes to extract core feature updates versus minor bug fixes.
- PDF Manual Analysis: Extracting specific action items and troubleshooting steps from complex technical manuals.
- Code Refactoring: Providing optimization suggestions for existing code snippets without altering the underlying logic or introducing syntax errors.
My metrics for success were not just "accuracy," but a composite score of latency (Time to First Token), system thermal impact, and edit distance (how much manual correction I had to perform on the model’s output).

Supporting Data: Capability vs. Practicality
The results of the test revealed a nuanced reality.
The Performance Gap
The gpt-oss:20b model consistently delivered more polished, sophisticated prose. In the PDF analysis phase, it demonstrated a superior ability to map cross-references within documents. When it came to code refactoring, it suggested more idiomatic solutions that aligned with modern best practices.
However, the deepseek-r1:14b model performed at roughly 90% of the capability of the 20B model across all tasks. Crucially, the 14B model operated with a 40% reduction in latency. In a work environment where I might query the model 50 to 100 times a day, the cumulative time saved by the 14B model amounted to nearly 20 minutes of active focus time.
The Resource Tax
The larger model pushed the system closer to its VRAM ceiling. While the RTX 5070 handled the 20B model well, the GPU utilization remained high, preventing me from running other hardware-accelerated tasks—such as video editing or compiling code—simultaneously. The 14B model, by contrast, allowed for a multi-threaded workflow where the AI felt like a background utility rather than a resource-heavy monolith.

Implications: The Death of the "One-Size-Fits-All" Model
The primary takeaway from this experiment is that the AI community must pivot away from a singular focus on model size. The "productivity tax" is real: if a model takes six seconds to think, you are likely to lose your train of thought, breaking the "flow state" that is essential for high-level engineering or writing.
The Case for a Hybrid Ecosystem
Rather than choosing one permanent model, the future of local AI lies in Model Routing. This is an architectural shift where a user employs a "fast" model (like a 7B or 14B variant) for 80% of daily tasks—summaries, quick questions, and basic syntax checks—and intelligently routes complex, multi-step logical problems to a "reasoning" model (like the 20B or even higher).
This hybrid approach acknowledges that:
- Contextual Complexity dictates model size: Simple summarization does not require a 20B parameter brain.
- Latency is a feature: In many professional contexts, a "good enough" answer delivered in 500ms is infinitely more valuable than a "perfect" answer delivered in five seconds.
- Hardware headroom is precious: Maintaining system responsiveness is key to long-term productivity.
Final Thoughts: Finding Your Sweet Spot
As I continue to iterate on my personal AI stack, my criteria for selecting a model have changed. I no longer ask, "What is the most intelligent model I can run?" Instead, I ask, "What is the most intelligent model that does not interrupt my rhythm?"
If you are currently struggling with a self-hosted setup that feels clunky, I urge you to scale down. You may find that by moving from a 20B+ model to a highly optimized 14B or even 8B parameter model, you don’t actually lose the utility you need. Instead, you gain the responsiveness necessary to make local AI feel like a natural extension of your mind, rather than a slow, demanding tool that requires you to work around its own limitations.
In the world of local AI, the best model is not the one with the most parameters; it is the one that stays out of your way. Whether you are a developer, a writer, or a data analyst, the goal should always be to maximize your output, not your parameter count. Keep your local stack lean, your latency low, and your workflow fluid.